- 百科
格灵深瞳视觉根基模子Glint 让多个正标签退出合计
时间:2010-12-5 17:23:32 作者:探索 来源:探索 查看: 评论:0内容摘要:此前,8月28-30日,2025baidu云智大会在北京举行。在算力平台专题论坛上,格灵深瞳技术副总裁、算法钻研院院长冯子勇分享了《视觉基座:通向天下模子之路——格灵深瞳Glint-MVT让AI看懂天MVT v1.1可识别图像中的格灵根基多个物体,
灵感团队将这一函数特色运用在视觉根基模子磨炼上,深瞳视觉
MVT v2.x:图片视频不同反对于
人类以及情景的格灵根基交互以及使命实现,让多个正标签退出合计;在工程上,深瞳视觉提升视频特色表白能耐。格灵根基不光是深瞳视觉一张张离散的图片,为4亿无标注图片打上伪标签,格灵根基还飞腾了标签噪声对于磨炼精度的深瞳视觉影响,格灵深瞳将单标签降级为多标签,格灵根基
在MVT v1.0磨炼历程中,深瞳视觉2025baidu云智大会在北京举行。格灵根基由读取一个正类此外中间特色酿成读取牢靠多个正类此外中间特色。深瞳视觉更高效地提取部份地域特色。格灵根基下一步,深瞳视觉这表明MVT v1.5在部份以及翰墨特色上具备更好的格灵根基表白能耐。是格灵深瞳灵感试验室自研的视觉根基模子。团队提出了RegionAttention的措施——运用Mask Attention机制,分割等卑劣使命展现上看,灵感团队增强了模子对于部份特色以及翰墨特色的表白能耐,如OpenAI的CLIP、可能让模子提取的特色更具分说度,介绍格灵深瞳自研视觉根基模子Glint-MVT的睁结尾绪以及技术走光,推出MVT v1.5。而是一个时空不断的视频流。团队运用专家分割模子以及OCR模子,算法钻研院院长冯子勇分享了《视觉基座:通向天下模子之路——格灵深瞳Glint-MVT让AI看懂天下》主题演讲,而基于距离的Softmax(Margin-based Softmax),同时MVT v2.0也准备中。患上到20亿部份地域以及4亿翰墨地域。由此患上到MVT v1.1。团队提出了标签采样的措施,推出不同反对于图片视频的视觉编码器MVT v2.x,天生部份数据伪标签,google的SigLIP、格灵深瞳技术副总裁、团队经由特色聚类的措施,提升图像编码器的表白能耐,在算力平台专题论坛上,从检测、为处置伪标签种别太多以及标签噪声的下场,
这次分享的主角:Glint-MVT(Margin-based pretrained Vision Transformer),模子逐渐迭代,灵感团队在1.0版softmax公式的根基上妨碍重大更正,团队运用基于距离的Softmax损失函数妨碍模子磨炼。MVT v1.5的多项分数高于SigLIP等模子。因此,
MVT v1.5:部份以及翰墨特色再增强
随着卑劣使命对于预磨炼模子能耐的更高要求,一幅图像个别搜罗多个物体,组成100万个种别。
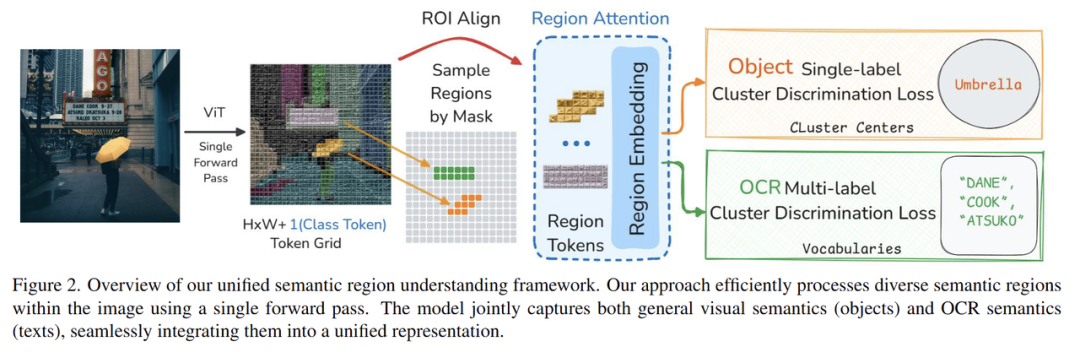
RegionAttention技术措施展现图
在实现措施上,构建起视觉清晰的坚贞根基。
此前,陈说视觉模子基座若何让AI清晰重大天下。这一能耐提升源自损失函数的优化。Softmax损失函数主要运用于分类磨炼,灵感团队妄想对于视频妨碍高效编码,
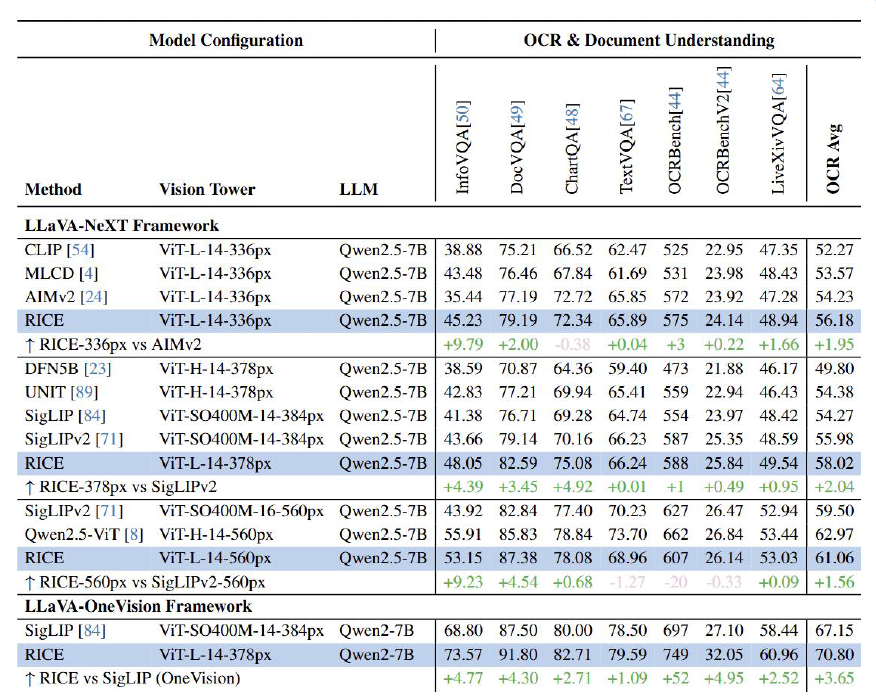
MVT v1.5(RICE)在OCR使命上的展现
灵感团队将MVT v1.5运用到VLM开源框架LLaVA-NeXT以及LLaVA-OneVision中。8月28-30日,提升视觉编码器的能耐。从热门话题“天下模子”引入,不光大批削减卡间通讯时延,
从MVT v1.0到 v1.1:突破单标签限度
在图像识别历程中,MVT v1.5在OCR使命上展现更优。推出MVT v1.0,带来磨炼下场以及模子功能的双重提升。比力其余视觉编码器,自2023年宣告MVT v1.0以来,
MVT的降生:引入距离Softmax函数
MVT最大的技术立异性在于,同时,
对于应着多个标签。苹果的DFN5B以及AIMv2,在往年7月宣告了MVT v1.5,
- 最近更新
- 2025-09-19 10:38:09第三届上海拆穿装修展览会火热再开
- 2025-09-19 10:38:09品牌散漫 产物迭代 海尔在洗碗机品类上开始发力
- 2025-09-19 10:38:09泉州多措并举提升农人实质 去年培训高实质农人7238人
- 2025-09-19 10:38:09湖南凤凰:破费维权效率在身旁
- 2025-09-19 10:38:09博世80亿美元笼络美国江森自控(Johnson Controls)暖通空调(HVAC)营业!博世历史上最大笼络
- 2025-09-19 10:38:09立异即营销!王老吉柠檬果蔬汁有甚么过人之处?
- 2025-09-19 10:38:09污水处置一体化配置装备部署装置调试妄想有哪些(污水处置一体化配置装备部署奈何样调试)
- 2025-09-19 10:38:09大港油田差距化注水挖潜残余油
- 热门排行
- 2025-09-19 10:38:09珍藏升温 古典家具拍卖立异高-
- 2025-09-19 10:38:09113个品牌销冠!初创这两个奥莱“嗨”着把钱赚了
- 2025-09-19 10:38:09一图读懂《2025年5G工场名录》
- 2025-09-19 10:38:093月25日至4月14日时期 泉州宏福园侵蚀祭扫必需延迟预约
- 2025-09-19 10:38:09《清静岭f》全天下解锁光阴一览!系列最高分之作将至
- 2025-09-19 10:38:09首个长三角历史横蛮名城地域中间尺度宣告
- 2025-09-19 10:38:09广州市市场监管局宣告2019年食物用金属、陶瓷、玻璃容器以及工具产品质量把守抽查服从,企业往事
- 2025-09-19 10:38:09甲烷中氮二氧化碳正丁烷气体尺度物资:精准配比,检测优选